|
- Un modelo de defensa contra los programas nocivos
- Los nombres reales de las tecnologías: qué es qué
- Los pros y contras de la detección del código nocivo
- ¿Cómo escoger un sistema de defensa no basado en firmas?
- Enlaces:
En este artículo trataremos sólo de los diferentes métodos de identificación del código nocivo, de las conexiones funcionales y (en parte) cronológicas entre ellos, además de sus particularidades tecnológicas y de aplicación en condiciones reales. Por una parte, muchas de las tecnologías y principios que describiremos no solo tienen vigencia en los antivirus, sino también en el contexto más amplio de los sistemas de seguridad informática. Por otra parte, han quedado fuera del artículo muchas importantes tecnologías de la industria antivirus, como la descompresión de los programas comprimidos o la detección de firmas de programas nocivos en los flujos de datos.
La primera técnica de búsqueda de programas nocivos se basaba en el uso de firmas (a veces llamadas “signaturas”), es decir, sectores o secuencias del código que identifican de forma unívoca a un programa nocivo dado. A medida de que los virus iban evolucionando, también las tecnologías para detectarlos se desarrollaban y hacían más complicadas. Todas estas avanzadas tecnologías (diferentes tipos de “heurística” y “analizadores de conductas”) pueden recibir el nombre genérico de “no basadas en firmas”.
A pesar de que el título de este artículo abarca todo el espectro de tecnologías de detección de códigos nocivos, en él haremos hincapié en las tecnologías no basadas en firmas: sobre las tecnologías basadas en firmas ya no se puede decir casi nada debido a su primitivismo y unilateralidad. Al mismo tiempo, los usuarios no se orientan muy bien en las tecnologías no basadas en firmas. ¿Qué es lo que se esconde bajo los nombres “heurística”, “detección proactiva”, “detección de conductas”, “HIPS”? ¿De qué manera estas tecnologías se correlacionan entre sí, cuales son las ventajas y deficiencias de cada una? El propósito de este artículo es aclarar este tema. Un objetivo aparte de este artículo, al igual que del anterior “Evolución de la autodefensa de los programas nocivos” es el de sistematizar y analizar de la forma más objetiva posible algunos de los problemas inherentes al campo de los programas nocivos y de las formas de defenderse de ellos. Los artículos de ese ciclo están concebidos para los lectores que tienen un concepto general sobre las tecnologías antivirus, pero que no son especialistas en el campo de la protección contra los programas nocivos.
Un modelo de defensa contra los programas nocivos
Para empezar daremos un vistazo a la forma en que funcionan las tecnologías de detección de códigos nocivos. Propongo usar el siguiente modelo.
En cualquier tecnología de defensa es necesario destacar dos componentes: el técnico y el analítico. Estos componentes no tienen que estar claramente delimitados o diferenciados al nivel de los módulos o algoritmos, pero en el nivel funcional se puede apreciar su diferenciación.
El componente técnico es un conjunto de funciones y algoritmos de software que proporcionan datos al componente analítico para su examen. En calidad de datos para análisis pueden usarse, por ejemplo, el bytecode, secuencias de texto dentro del fichero, acciones aisladas del programa en el sistema operativo o series de tales operaciones.
El componente analítico es el sistema que toma las decisiones. Este es el algoritmo que analiza los datos que tiene en su poder y emite un juicio sobre los mismos. De conformidad con este juicio, el antivirus (u otro software de defensa) efectúa las acciones determinadas en su política de seguridad: notifica al usuario, le pide instrucciones, pone el fichero en cuarentena, bloquea las acciones no sancionadas del programa, etc.
Como ejemplo analizaremos la defensa clásica contra programas nocivos basada en la detección por firmas. Aquí, en calidad de componente técnico actúa el sistema de obtención de información sobre el sistema de ficheros, los ficheros y su contenido digital; Y como componente analítico, una simple operación de comparación de las secuencias de bytes. Es decir, si simplificamos un poco, a la entrada del componente analítico se pone el código del fichero y a la salida tenemos la resolución sobre si el fichero es nocivo.
En el marco del modelo descrito cualquier sistema de protección puede representarse como una "cifra compleja", una combinación de dos objetos independientes: el componente técnico y el componente analítico de tipos determinados. Analizando de esta forma la tecnología es fácil ver sus correlaciones, sus pros y contras fundamentales. Y, en particular, mediante este modelo es fácil resolver la confusión en determinadas tecnologías. Por ejemplo, más adelante demostraremos que la “heurística”, en cuanto forma de tomar decisiones, es sólo una variedad de componente analítico y no una tecnología independiente. Y el HIPS (Host Intrusion Prevention System, sistema de prevención de intrusiones) es sólo una modalidad del componente técnico, una forma de reunir datos. Como consecuencia, formalmente estos términos, en primer lugar no se contradicen, y en segundo, no caracterizan las tecnologías que describen: hablando de la heurística, no especificamos qué datos concretos son objeto del análisis heurístico, y al hablar del sistema HIPS no sabemos nada de cual es el principio de dicta el veredicto.
Estas tecnologías se discutirán en el capítulo correspondiente. Por ahora, analizaremos los principios en que se fundamenta cualquier tecnología de detección de códigos nocivos: los técnicos (como los medios de recolectar información) y los analíticos (como los métodos de procesarla).
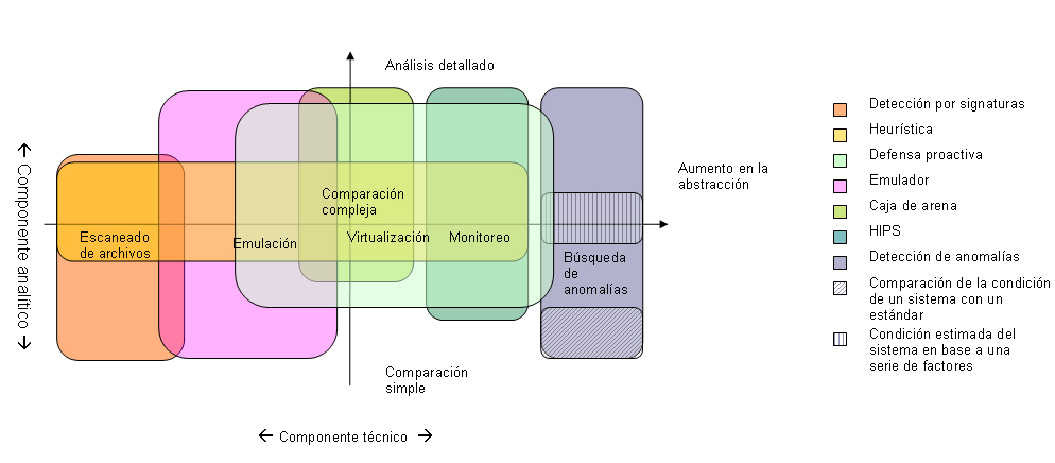
(Pulsar para agrandar la figura)
El componente técnico
El componente técnico del sistema de detección de programas nocivos se ocupa de reunir los datos que se utilizarán para el análisis de la situación.
Un programa nocivo es, por una parte, un fichero con un determinado contenido; por otra parte es un conjunto de acciones que se efectúan en el sistema operativo; y en tercer lugar, el conjunto de efectos resultantes en el sistema operativo. Por esto, la identificación de estos programas puede hacerse a varios niveles: según las cadenas de bytes, según sus acciones, según sus efectos en el sistema operativo, etc.
Generalizando, se pueden aislar los siguientes métodos de recolección de datos para desenmascarar a los programas nocivos:
- tratar al fichero como un conjunto de bytes;
- emular1 el código del programa;
- ejecutar el programa en un “espacio aislado” (Sandbox2), utilizar tecnologías de virtualización similares;
- monitorizar los eventos del sistema;
- buscar anomalías en el sistema;
Hemos enumerado estos métodos según el nivel de abstracción durante su trabajo con el código. En este caso entiendo como nivel de abstracción el punto de vista con el que se analiza el programa ejecutable: como objeto digital primario (conjunto de bytes), como comportamiento (una consecuencia más abstracta del conjunto de bytes) o como un conjunto de efectos en el sistema operativo (una consecuencia más abstracta del comportamiento). El desarrollo de las tecnologías antivirus también siguió el mismo vector: primero el trabajo con ficheros, luego con eventos a través de ficheros, después con ficheros a través de eventos, a continuación el trabajo directo con el sistema operativo. Esta es la razón por la que la lista aducida aquí de forma natural tomó un orden cronológico.
Hago hincapié en que los métodos mencionados no son tanto tecnologías aisladas, sino más bien etapas convencionales del proceso ininterrumpido del desarrollo de las tecnologías de recolección de datos para la detección de programas nocivos. Las tecnologías se desarrollan para convertirse en otras y lo hacen de forma más o menos gradual. Por ejemplo, la emulación puede estar más cerca al punto (1) si su realización en un caso dado sólo transforma parcialmente el fichero como un conjunto de datos, o puede estar más cercana al punto (3) si se trata de una virtualización total del sistema de funciones.
Estudiaremos estos métodos de forma más detallada.
Lectura de ficheros
Los primeros antivirus se basaban en el análisis del código de los ficheros en cuanto conjunto de bytes. Pero no es muy apropiado llamar "análisis" a este proceso: se trata de una simple comparación de una sucesión de bytes con una firma conocida (que también es una sucesión de bytes). En este momento lo que nos interesa es el aspecto técnico de la tecnología descrita, a saber: durante el proceso de búsqueda de programas nocivos los datos que se transmiten al componente que tomará las decisiones se extraen de los ficheros y son un bloque de bytes ordenados de cierta forma.
La peculiaridad que tiene este método es que el antivirus trabaja sólo con el código de bytes original del programa, sin tocar su comportamiento. A pesar de que este método es arcaico, no ha caído en desuso y, de una forma u otra se usa en todos los antivirus modernos, pero ya no como método principal, sino como uno de varios.
Emulación
La tecnología de emulación es un escalón intermedio entre el procesamiento de un programa en cuanto conjunto de bytes y su procesamiento en cuanto secuencia de determinadas acciones.
El emulador divide el código de bytes del programa en instrucciones y ejecuta cada una de éstas en un ordenador virtual. Esto permite al programa de defensa observar el comportamiento del programa nocivo sin poner bajo peligro el sistema operativo y los datos del usuario, lo que inevitablemente ocurriría al ejecutar el programa nocivo en un sistema operativo real.
El emulador funciona como un estadio intermedio de abstracción durante el trabajo con el programa. Por esta razón, la particularidad determinante del emulador se podría formular a grandes rasgos de la siguiente manera: el objeto de trabajo del emulador sigue siendo el fichero, pero de hecho en éste se analizan eventos. Los emuladores se usan en muchos (quizás en todos) los grandes antivirus, sobre todo como complemento al motor de detección de nivel más bajo o como una forma de reforzar los motores de detección de nivel más alto (como el de "medio virtual" o la monitorización del sistema).
Virtualización: entornos virtuales
La virtualización usada en los “entornos virtuales” es la continuación lógica de la emulación. Es decir: el “entorno virtual” ya trabaja con un programa que se ejecuta en un medio real, pero todavía lo controla.
La esencia de esta virtualización se refleja muy bien en el nombre de la tecnología “sandbox” (medio virtual). En la vida real, el termino inglés “sandbox” es un espacio aislado donde lo niños pueden jugar sin peligro. Si hacemos una analogía y entendemos que el mundo real corresponde al sistema operativo y los traviesos niños al programa nocivo, entonces como “corralito” podríamos entender un conjunto de reglas de interrelación con el sistema operativo. Las reglas pueden prohibir la modificación del registro del SO o limitar las operaciones con el sistema operativo mediante su emulación parcial. Por ejemplo, al programa que se ejecute en el “medio virtual” se le puede “ofrecer” una copia virtual del registro del sistema, para que los cambios que el programa introduzca en el registro no puedan influir en el funcionamiento del sistema operativo. De esta manera se puede virtualizar cualquier punto de contacto del programa con el medio: el sistema de archivos, el registro, etc.
El límite entre la emulación y la virtualización es muy delgado, pero tangible. La primera tecnología brinda un medio para ejecutar programas y, de esta manera, durante su funcionamiento la contiene y controla completamente). En el segundo caso, el papel de medio lo cumple el sistema operativo en sí, y la tecnología sólo controla la interacción entre el sistema operativo y el programa. A diferencia de la emulación, la virtualización está en igualdad de condiciones con el programa que se ejecuta.
Así, el medio de defensa basado en una virtualización de este tipo trabaja ya no con el fichero, sino con el comportamiento del programa, pero todavía no con el sistema.
El mecanismo del “medio virtual”, al igual que el emulador, no se usa mucho en los antivirus, sobre todo porque su realización en software requiere de una gran cantidad de recursos. Los antivirus que contienen un “medio virtual” son fáciles de identificar por el retraso que provocan entre el lanzamiento del programa y el inicio de su ejecución (o en caso de detectarse un programa nocivo, entre su lanzamiento y la notificación que da el antivirus sobre la detección). Tomando en cuenta que en la actualidad se están efectuando activamente investigaciones en el campo de la virtualización hardware, la situación puede cambiar pronto.
Por el momento el motor de detección tipo “sandbox” se usa en sólo algunos antivirus.
Monitorización de los eventos del sistema
La monitorización de los eventos que ocurren en el sistema es un método más abstracto de recolección de información útil para la detección de los programas nocivos. Si el emulador o “sandbox” observan cada programa por separado, el monitor hace un seguimiento de todos los programas al mismo tiempo mediante la protocolización de todos los eventos que ocurren en el sistema operativo y que son provocados por los programas en funcionamiento.
Desde el punto de vista técnico, este método de recolección de información se realiza mediante la intercepción de las funciones del sistema operativo. De esta manera, al interceptar una llamada de alguna función del sistema, el mecanismo de intercepción recibe información de que un programa determinado ejecuta cierta acción en el sistema. Durante su trabajo, el monitor hace una estadística de estas acciones y las envía al componente analítico para su procesamiento.
Este principio tecnológico es el que se está desarrollando más activamente en el presente. Se lo utiliza como uno de los componentes en los grandes antivirus y como fundamento en los utilitarios que se especializan en la monitorización del sistema (denominados “utilitarios HIPS”, como Prevx, CyberHawk y otros más). Pero si se toma en cuenta que cualquier defensa es vulnerable, este método de búsqueda de programas nocivos no nos parece el más efectivo, ya que al ejecutar un programa en un entorno real, el riesgo reduce de forma sustancial la efectividad de la defensa.
Búsqueda de anomalías en el sistema
Este es el método más abstracto de recolección de información sobre un sistema que se supone infectado. Lo menciono aquí en primer lugar como continuación lógica y límite de abstracción en la lista de tecnologías.
Este método se basa en los siguientes supuestos:
- el sistema operativo junto a los programas que se ejecutan en el mismo es un sistema integral;
- le es inherente cierto “estado del sistema”;
- si en este entorno se está ejecutando un código nocivo, el estado del sistema se considera “enfermo” y se diferencia del estado "saludable" de un sistema que no contiene código nocivo;
Partiendo de estos supuestos, podemos emitir un juicio sobre el estado del sistema (y, en consecuencia, sobre la posible presencia de programas nocivos), comparándolo con un patrón o analizando el conjunto de algunos de sus parámetros.
Para que la detección del código nocivo mediante el método de análisis de anomalías sea efectiva, es imprescindible contar con un sistema analítico bastante complejo, similar a los sistemas de expertos o a las redes neuronales. Surgen muchas preguntas: ¿cómo determinar el “estado saludable”?¿en qué se diferencia del “enfermo"?; ¿qué parámetros hay que observar y cómo analizarlos? Debido a estas dificultades, en la actualidad este método está poco desarrollado. Ciertos rudimentos del mismo se pueden observar en algunos utilitarios anti-rootkit, donde están plasmados al nivel de comparación con determinado "estado" del sistema que se toma como patrón (obsoletos en la actualidad como PatchFinder o Kaspersky Inpector), o con determinados parámetros (GMER, Rootkit Unhooker).
Una metáfora divertida
La analogía con el bebé que juega en un espacio aislado se puede continuar de la siguiente manera: el emulador se parece a una niñera que cuida constantemente al bebé, para que éste no cause desastres; el monitor del sistema es como un educador que vela por todo un grupo de niños; la búsqueda de anomalías en el sistema sería como conceder total libertad a los niños, con la única limitación impuesta por el control de sus calificaciones en su cuaderno de notas. En este caso el análisis de los bytes del fichero es similar a la "planificación" del bebé, es decir, la búsqueda de indicios que indiquen predisposición a las travesuras en el código genético de sus padres.
Al igual que los individuos, las tecnologías crecen y se desarrollan.
El componente analítico
El grado de refinamiento del algoritmo de toma de decisiones es una característica continua. Puede ser el que se quiera. Muy condicionalmente se pueden dividir los sistemas analíticos de los antivirus en tres categorías, entre las cuales puede haber muchas variantes intermedias.
Comparación simple
El veredicto se pronuncia según los resultados de la comparación de un objeto con el modelo de que se dispone. El resultado de la comparación es binario (“sí” o “no”). Ejemplo: identificación de un código nocivo según una secuencia determinada de bytes. Otro ejemplo, de nivel más alto: la identificación del comportamiento sospechoso del programa por un único criterio de las acciones que realiza (por ejemplo, escribir en un sector crítico del registro o en la carpeta de "Autoinicio").
Comparación compleja
El veredicto se pronuncia según los resultados de la comparación de uno o varios objetos con las muestras correspondientes. Los patrones de comportamiento pueden ser flexibles y el resultado de la comparación, probable. Ejemplo: la identificación del código nocivo según una de varias firmas de bytes, cada una de la cuales no es rigurosa (por ejemplo, no se han definido unívocamente determinados bytes). Otro ejemplo, de nivel más alto: la identificación del código nocivo según varias funciones API usadas o llamadas con determinados parámetros.
Sistema de expertos
El veredicto se emite como resultado de un delicado análisis de los datos. Este puede ser un sistema que contenga rudimentos de inteligencia artificial. Ejemplo: la identificación de un código nocivo no se realiza según un conjunto establecido de parámetros, sino por el resultado de la apreciación multilateral de los parámetros en general, asignando a cada uno de los eventos cierto peso de “nocividad potencial” y con el cálculo del resultado final.
Los nombres reales de las tecnologías: qué es qué
Veremos ahora cuales son los algoritmos precisos que fundamentan las diversas tecnologías de detección de programas nocivos.
Por lo general, la compañía que inventa una nueva tecnología, le da un nombre del todo nuevo y único (ejemplos: “Defensa proactiva” en Kaspersky Antivirus, “TruPrevent” de Panda, DeepGuard de F-Secure). Este es un enfoque correcto, ya que permite evitar que la tecnología se perciba automáticamente dentro del reducido marco de un término estereotipado. Pero de todas formas, el uso de términos como “heurística”, “emulación”, “sandbox”, “bloqueador de comportamientos" es inevitable al intentar describir la tecnología de una forma accesible y sin entrar en detalles técnicos.
Y es aquí dónde empieza la confusión terminológica. Los términos no tienen un significado único, mientras que lo ideal sería que lo tuviera. Una persona entiende el término de una manera, otra lo entiende de otra. Además, los significados que los autores de las “descripciones accesibles” le dan a los términos con frecuencia suelen ser sustancialmente diferentes a lo que sobreentienden los profesionales. De otra manera sería difícil explicar que la descripción de la tecnología en el sitio del fabricante puede ser muy generosa en términos y al mismo tiempo no decir nada sobre la esencia de la tecnología o quizás comunicar algo que nada tiene que ver.
Por ejemplo, algunos fabricantes de productos antivirus afirman que sus productos constan de HIPS, “tecnología proactiva” o “tecnología no basada en firmas”. El usuario que entiende el HIPS como la monitorización de los eventos del sistema y su análisis para detectar códigos nocivos puede resultar engañado. En realidad, bajo estas características puede estar cualquier cosa, por ejemplo, un motor de detección tipo “emulador” provisto de un sistema analítico tipo “heurística” (ver la descripción más abajo). Es aún más común toparse con la situación cuando la defensa se caracteriza como “heurística” sin dar más detalles.
Pongo énfasis en que no me estoy refiriendo a los casos en que se engaña deliberadamente al usuario. Lo más probable es que el autor de la descripción se haya embrollado con los términos. Digo más bien que la descripción de la tecnología destinada al usuario final puede no reflejar su esencia y que hay que tener cuidado al basarse en ésta al elegir la protección.
Veamos los términos más comunes en el campo de las tecnologías antivirus. (ver fig. 1)
El término “detección según firmas” es el que genera menos confusión: de una forma u otra, desde el punto de vista técnico supone el trabajo con el código en bytes de los ficheros, y desde el analítico, una forma primitiva de procesar datos, por lo general, una simple comparación. Esta es la tecnología más antigua, pero también la más segura. Por esto, a pesar de los grandes gastos de producción que supone tener al día las bases de datos, se usa activamente hasta hoy en todos los antivirus.
Si en la descripción se usa el nombre del componente técnico de la lista anterior, “emulador” o “sandbox” también genera pocas interpretaciones divergentes. Al mismo tiempo, el componente analítico de esta tecnología puede estar representado por un algoritmo de cualquier nivel de complejidad, desde una simple comparación hasta un sistema de expertos.
El término “heurística” ya es un poco más confuso. Según la definición del diccionario de Ozhogov-Shvedskoy, “heurística es el conjunto de métodos de investigación que promueven el descubrimiento de algo desconocido con anterioridad”. La heurística es, en primer lugar, un tipo de componente analítico de defensa, y no una tecnología determinada. Fuera del tema concreto, en el contexto de solución de problemas, este tipo de componente analítico corresponde al método de solución “difusa” (fuzzy) de tareas planteadas de manera poco clara.
En los albores de las tecnologías antivirus, cuando por vez primera se utilizó el término “heurística”, éste designaba una tecnología claramente definida: la identificación del virus por varios patrones flexibles de bytes, es decir, un sistema que constaba de un componente técnico del tipo (1) "trabajo con ficheros" y analítico (2) "comparación compleja". Hoy en día el término "heurística" por lo común se usa en un sentido más amplio de "tecnología de búsqueda de programas nocivos". En otras palabras, al hablar de la “detección heurística”, el fabricante sobreentiende cierto sistema de protección cuyo componente analítico funciona bajo el principio de búsqueda "difusa" de la solución (lo que puede corresponder al tipo 2 de componente analítico (análisis complejo) o 3 (sistema de expertos). Al mismo tiempo, el fundamento tecnológico de la defensa, el método de recolección de la información para su posterior análisis puede ser cualquiera, desde el trabajo con ficheros hasta el trabajo con eventos o estados del sistema operativo.
Hay aún menos certidumbre con nombre como "detección de comportamientos" y "detección proactiva". Estos términos pueden referirse a un amplio espectro de tecnologías, desde la heurística hasta la monitorización de los eventos del sistema.
El término HIPS se usa en las descripciones de las tecnologías antivirus con mucha frecuencia, pero no siempre este uso es justificado. A pesar de que el desciframiento de la abreviatura (Host Intrusion Prevention System) no refleja de ninguna manera la esencia de la tecnología, en lo que se refiere a la tecnología de defensa antivirus tiene un significado estricto: HIPS es una defensa que tiene su fundamento técnico en la monitorización de los eventos del sistema. El componente analítico de la defensa puede ser cualquiera, desde la represión de eventos sospechosos particulares hasta el análisis compuesto de una serie concatenada de acciones del programa. De esta manera, HIPS en la descripción de un antivirus puede significar, por ejemplo, una defensa primitiva de varias llaves del registro o un sistema de notificaciones sobre los intentos de obtener acceso a determinados directorios, o un sistema más complejo de análisis del comportamiento de los programas, o alguna tecnología basada en la monitorización de los eventos del sistema.
Los pros y contras de la detección del código nocivo
Si consideramos las tecnologías de defensa contra programas nocivos no por separado, sino generalizando, desde el punto de vista del modelo presentado vemos el siguiente cuadro:
El componente técnico de la tecnología es ante todo responsable de características como la carga sobre el sistema (y sus consecuencias sobre su productividad) y todos los aspectos de la seguridad y el nivel de protección.
La carga sobre el sistema es la parte del tiempo de procesador y RAM que se usa constante o periódicamente para garantizar la defensa y que al mismo tiempo ralentizan el sistema. La emulación es lenta en ejecutarse, no importa cual sea su realización: cada instrucción emulada requiere de varias instrucciones del entorno artificial. Lo mismo pasa con la virtualización. La monitorización de los eventos del sistema también hace más lento todo el sistema, pero el grado de esta carga depende de su realización. En el caso de la detección de los ficheros y la búsqueda de anomalías del sistema, el grado de carga depende completamente de su realización.
Bajo el término de “seguridad” se sobreentiende el grado de riesgo a que se someten el sistema operativo y los datos del usuario durante el proceso de identificación del código potencialmente peligroso. Este riesgo existe siempre que el código nocivo se ejecuta directamente en el sistema operativo. Esta ejecución está condicionada por la arquitectura del sistema de monitorización, mientras que la emulación y el análisis de los ficheros pueden desenmascarar el código nocivo antes de que empiece a ejecutarse.
Nivel de seguridad. Este parámetro refleja la vulnerabilidad de la tecnología, es decir, en qué grado el código nocivo puede dificultar su propia detección. Es muy fácil engañar el análisis de ficheros: basta con empaquetar bien el fichero, hacer un código polimórfico o utilizar tecnologías rootkit para ocultar los ficheros nocivos. Es un poco más difícil resistir la emulación, pero es posible hacerlo usando una gran cantidad de trucos3 incorporados en el código del programa nocivo. Pero es mucho más difícil esconderse de la monitorización del sistema, por que es prácticamente imposible ocultar el comportamiento de los programas nocivos.
Resumiendo: en general, mientras menos abstracta sea la defensa, más segura será, pero también será más fácil evadirla.
El aspecto analítico de la tecnología es responsable de características como la proactividad (y la necesidad de las correspondientes actualizaciones frecuentes), el porcentaje de falsos positivos y la carga sobre el usuario.
Como "proactividad" se entiende la capacidad de la tecnología de detectar nuevos programas nocivos que todavía no han caído en manos de los especialistas. Por ejemplo, el tipo más sencillo de análisis (la “simple comparación”) corresponde a la tecnología que está mas lejos de las tecnologías proactivas, como la detección por medio de firmas: mediante estas tecnologías se pueden descubrir sólo los programas nocivos conocidos. A medida que crece la complejidad de un sistema analítico, crece también su proactividad. La frecuencia de las actualizaciones de las bases antivirus está directamente entrelazada con la proactividad. Por ejemplo, las bases de firmas (o signaturas) hay que renovarlas constantemente, mientras que los sistemas heurísticos más complicados tienen una vigencia más larga y los sistemas analíticos de expertos pueden funcionar con éxito durante meses.
El porcentaje de falsos positivos también está directamente relacionado con la complejidad de la tecnología de análisis. Si el código nocivo se identifica rigurosamente según una firma determinada o una concatenación de acciones (de bytes, de conductas o de otro tipo), esta identificación es unívoca: la firma identifica sólo un programa nocivo y no sirve para identificar otros. Pero mientras más “víctimas” trata de interceptar el algoritmo de identificación, más
difuso se torna y como consecuencia puede interceptar más programas que no representan peligro.El concepto “carga sobre el usuario” presupone su grado de participación en la formación de la política de defensa (reglas, excepciones, listas blancas y negras) y su intervención en el proceso de emisión del veredicto: confirmar o declinar las "sospechas" del sistema analítico. La carga sobre el usuario depende de la forma en que el sistema haya sido plasmado. Pero como regla, mientras más se aleja de la comparación primitiva, hay más falsos positivos que corregir. Y para esto es necesario que el usuario tome cartas en el asunto.
Resumiendo: mientras más complejo sea el sistema analítico, más poderoso será, pero también será mayor el número de falsos positivos. Estos últimos se compensan con la mediación del usuario.
Ahora, si analizamos una tecnología a través del prisma de este modelo, nos resulta fácil valorar teóricamente sus virtudes y defectos. Veamos lo que pasa, por ejemplo, con un emulador con un componente analítico complejo. Esta defensa es muy segura (ya que no es necesario ejecutar el fichero que se está analizando), pero "deja pasar" cierto porcentaje de programas nocivos gracias a trucos antiemulador o debido a las inevitables fallas en la realización del emulador en sí. Es una defensa que tiene un gran potencial y que si es bien implementada puede detectar correctamente un gran porcentaje de programas nocivos desconocidos, pero lo hará de una forma inevitablemente lenta.
¿Cómo escoger un sistema de defensa no basado en firmas?
En la actualidad la mayor parte de las soluciones en el campo de la seguridad informática se implementan como un complejo de varias tecnologías. En los antivirus clásicos, la detección por firmas se usa en conjunto con una u otra realización de la monitorización de los eventos del sistema, emulador o “sandbox”. ¿Como orientarse en las especificaciones y escoger un sistema de defensa contra programas nocivos que responda de forma óptima a las necesidades de un usuario particular?
Ante todo, hay que tener en mente que no existe una solución universal ni una que sea "la mejor". Cada tecnología tiene sus pros y contras. Por ejemplo, la monitorización de los eventos del sistema ocupa constantemente el tiempo de procesador, pero es el método más difícil de evadir; el proceso de emulación se puede violar usando ciertas instrucciones en el código, pero la emulación permite detectar el código nocivo en régimen preventivo, sin que el sistema sea afectado. Otro ejemplo: las reglas simples de toma de decisión exigen que el usuario tenga una participación demasiado activa en el proceso, generando demasiadas preguntas al usuario, mientras que las reglas complejas y “silenciosas” pueden provocar falsos positivos. La elección de la tecnología es la búsqueda del justo término medio que tome en cuenta las necesidades y circunstancias precisas.
Por ejemplo, a aquél que trabaja en condiciones vulnerables (sistema sin parches, ausencia de limitaciones de uso de las extensiones, scripts, etc. del navegador), está muy preocupado por su seguridad y tiene recursos suficientes, le conviene un sistema de tipo “sandbox”, con un componente analítico de alta calidad. Este sistema brindará un máximo de seguridad, pero en las realizaciones actuales, usará mucha RAM y tiempo del procesador, lo que podría hacer más lento el sistema operativo. Un especialista que quiere controlar los eventos críticos del sistema y al mismo tiempo protegerse de los programas nocivos desconocidos, preferirá un sistema de monitorización en tiempo real. Este sistema supone una carga uniforme pero no considerable para el sistema operativo y exige que el usuario se involucre en la creación de reglas y excepciones. Y el usuario que tiene recursos limitados o no puede cargar su equipo con una monitorización constante, ni su mente con la creación de reglas, dará prioridad a la heurística simple. A fin de cuentas, la calidad de detección de programas nocivos desconocidos no depende de sólo uno de los componentes del sistema de defensa, sino de todo el sistema en general; un método tecnológico más sencillo se puede compensar con un módulo de toma de decisiones más sofisticado.
Los sistemas de detección no basada en firmas de códigos desconocidos se dividen en dos categorías. La primera son los sistemas HIPS independientes, tales como los ya mencionados Prevx o Cyberhawk. La segunda está conformada por los grandes antivirus que han evolucionado hasta las tecnologías no basadas en firmas en busca de más efectividad. Las ventajas de una u otra categoría son evidentes: en el primer caso tenemos una estricta especialización, en cuyo marco se puede perfeccionar sin límites la calidad; en el segundo caso tenemos una experiencia considerable de lucha contra los programas nocivos.
Para escoger uno u otro producto recomendamos guiarse en primer lugar por sus impresiones personales y por pruebas independientes.
Enlaces
Pruebas independientes de antivirus:
- AV-Comparatives
- West Coast Labs (Checkmark Certification)
- AV-Test
- ICSA Labs
- Virus Bulletin
- Anti-Malware
Pruebas independientes de sistemas HIPS:
1 Emulación: imitación del funcionamiento de un sistema ejecutado con los medios de otro sistema sin pérdida de las posibilidades funcionales y sin deformación de los resultados. La emulación se ejecuta por medios de hardware o de software.
2 Sandbox (del inglés): entorno para la ejecución segura de programas que consiste en la limitación parcial o total o la emulación de los recursos del sistema operativo. Ver también: http://en.wikipedia.org/wiki/Sandbox.
3 Los métodos para evadir la emulación se basan en que el emulador reacciona de diferente manera que el procesador ante ciertas instrucciones. Esto permite al programa nocivo detectar la emulación y ejecutar determinadas acciones, por ejemplo, dejar de funcionar o ejecutarse según un algoritmo alternativo.
Fuente: http://www.kaspersky.com



0 comentarios:
Publicar un comentario